
Wenn es um generative KI geht, also um Inhalte erschaffende künstliche Intelligenz, dann ist für deren Stärke, aber auch für ihre letztendliche Nutzung oft eine gewisse Token-Anzahl wichtig. Doch was sind KI-Tokens? Was sagt die Menge an möglichen Tokens pro eingegebenem Befehl („Prompt“) und ausgegebener Antwort aus? Was kann man sich unter den Token-Kosten vorstellen, die ein bestimmtes Abonnement oder die API-Nutzung bringt? Und was ist der Unterschied zwischen Tokens und der Token-ID? Im Folgenden habe ich euch alle wichtigen Fakten zum Thema zusammengefasst.

Kapitel in diesem Beitrag:
- 1 Was sind KI-Tokens?
- 2 Durchschnittliche Token-Werte bei ChatGPT
- 3 Die Limitierung von Tokens für die Eingabe und Ausgabe
- 4 Google Gemini 1.5 mit bis zu 1 Million Tokens
- 5 Was ist eine Token-ID?
- 6 Die Token-ID am Beispiel von ChatGPT
- 7 Die Token-IDs der eigenen ChatGPT-Eingabe prüfen: So geht’s!
- 8 Fazit zu den Themen KI-Token und Token-ID
- 9 Ähnliche Beiträge
- 10 Qi2-Ladegerät mit Lüfter: Perfekt für den Sommer oder kompletter Quatsch?
- 11 Soundcore AeroClip: Open-Ear-Kopfhörer mit offenem Ring-Design
- 12 Mit MagSafe und Qi2: Pitaka Powerbank fürs iPhone ausprobiert
- 13 Was ist eine „virtuelle Softwarekarte“ auf der Nintendo Switch?
- 14 iVANKY Fusion Dock Pro 3 – 11-in-1 Thunderbolt 5 Dock günstiger kaufen
- 15 Mac-Hilfe: Bluetooth deaktiviert und Maus / Trackpad lässt sich nicht mehr nutzen
- 16 Manus – KI-Agent für komplexe Aufgaben (+ Open-Source-Alternative)
- 17 Europäischer Suchindex: Ecosia und Qwant arbeiten an Google-Alternative
Was sind KI-Tokens?
Einzelne Tokens sollte man sich nicht unbedingt als Währung vorstellen, die 1:1 auf bestimmte Eingaben oder Zeichen angerechnet werden können. Es sind eher Näherungswerte bzw. gerundete Werte. Zudem können sie je nach Sprache variieren. Die „Muttersprache“ der meisten großen KIs ist dabei Englisch, weshalb Eingaben in dieser Sprache vergleichsweise weniger Tokens bedeuten als Eingaben in anderen Sprachen – etwa Deutsch. Kürzere und einfachere Eingaben und Ausgaben sind dabei weniger Tokens wert als lange, komplexe Eingaben und Ausgaben.
Durchschnittliche Token-Werte bei ChatGPT
Will man nun also ermitteln, wie viele oder wie komplexe Prompts man mit einer bestimmten Token-Menge (etwa jene, die einem gewissen Budget gleichkommen) erstellen kann, ist diese allgemeine Beschreibung wenig zielführend. Nur zum Einsparen von Tokens hilft sie, da es beim Verständnis dafür hilft, dass in kürzerer Form eingegebene Inhalte weniger Verarbeitungsaufwand verursachen als komplexere und mit vielen Details gespickte Eingaben.
OpenAI gibt für die Nutzung von ChatGPT daher ein paar Leitwerte vor, an denen man sich orientieren kann. So hat man die Möglichkeit, die nötige Token-Menge für Prompts vorab einzuschätzen und sich die im jeweiligen Abonnement bzw. bei der Nutzung der ChatGPT-API entstehenden Kosten auszumalen. Hier die etwaigen Werte, die OpenAI für ChatGPT-Tokens angibt:
- 1 Token sind rund 4 Zeichen in Englisch
- 1 Token sind also etwa 3/4 eines durchschnittlichen englischen Wortes
- 100 Tokens sind damit rund 75 Wörter in Englisch
Weiterhin gibt es folgende Schätzungen für die englische Sprache:
- Ein bis zwei Sätze entsprechen rund 30 Tokens
- Ein Absatz sind ungefähr 100 Tokens
- Ein Text mit 1.500 Wörtern sind rund 2.048 Tokens
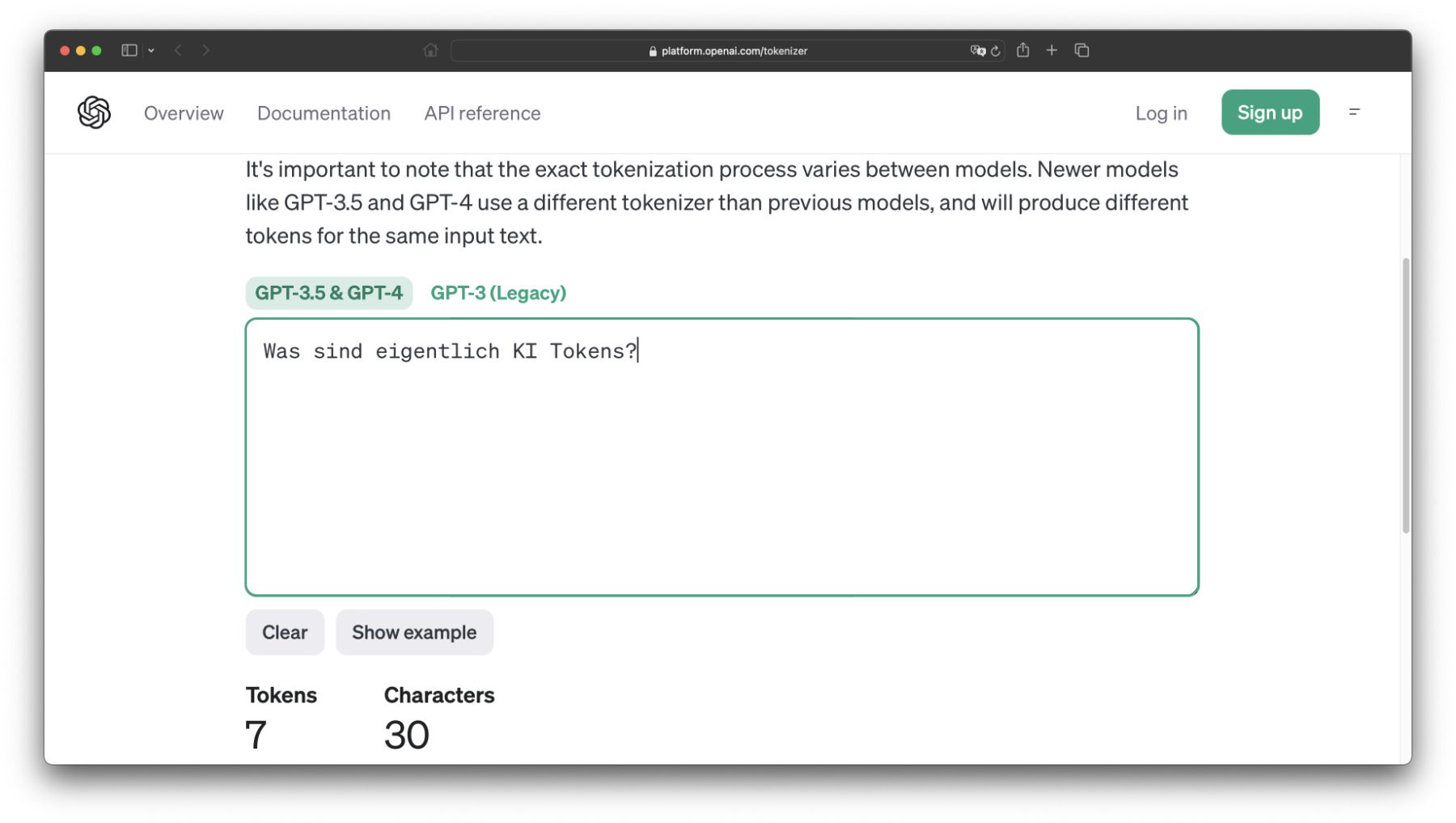
Das sind, wie angegeben, nur Schätzwerte. Sie können, gerade bei der Verwendung längerer Wörter, aber auch bei der Nutzung anderer Sprachen abweichen. OpenAI bietet für die genauere Berechnung von Tokens daher ein eigenes Web-Tool an, den Tokenizer. Dieser gibt etwa an, dass der deutsche Satz „Was sind eigentlich KI Tokens?“ nicht nur aus 30 Zeichen, sondern auch aus 7 Tokens besteht. Hier könnt ihr den Tokenizer für ChatGPT selber ausprobieren.
Die Limitierung von Tokens für die Eingabe und Ausgabe
Man kann sich fragen: Was soll das Ganze? Nun, Entwicklerfirmen von generativen KIs können mit Token-Mengen angeben, wie komplex eine KI „denken“ kann, also wie aufnahmefähig sie ist und wie umfangreich die möglichen Antworten ausfallen können. Ist eine KI auf wenige Tokens beschränkt, dann ist sie nicht sehr stark.
Kann die KI aber sehr viele Tokens pro Eingabe aufnehmen bzw. verarbeiten und schafft dann eine Ausgabe zahlreicher Tokens als Antwort, gilt sie als stark – der Umstand, dass Eingabe und Ausgabe inhaltlich zusammenpassen und der ausgegebene Inhalt sinnvoll ist, muss natürlich auch beachtet werden. Ist dieser aber gegeben, steigt mit der möglichen Token-Anzahl die Komplexität der KI.
So erklären sich auch die Nutzungskosten, etwa der ChatGPT-API. Eingaben kosten da für GPT-4 Turbo aktuell $0,01 pro 1.000 eingegebenen Tokens und $0,03 pro 1.000 ausgegebenen Tokens. Für GPT-4 werden für die Eingabe $0,03 pro 1.000 Tokens und $0,06 pro 1.000 ausgegebenen Tokens abgerufen. So lässt sich die Nutzung von Chatbots und multimodalen KIs monetarisieren. Denn nicht jede Anfrage und Antwort kann extrem kurz gehalten werden. Und gerade die Auswertung von PDFs und dazu beantwortete Fragen sind tokenlastig.
Google Gemini 1.5 mit bis zu 1 Million Tokens
Letztens habe ich euch ja schon aufgezeigt, dass Google seine „Bard“-KI in „Gemini“ umbenannt hat. Damit wurde zudem Gemini 1.0 veröffentlicht und der Bezahlzugang zur einer Ultra-Variante eingeführt. Nicht viel später wurde das noch nicht für die breite Masse zugängliche Modell Gemini 1.5 vorgestellt. Dieses soll pro Prompt mit bis zu 1.000.000 Tokens (Eingabe + Ausgabe) umgehen können. Nach der oben gegeben Erklärung zeigt diese Aussage deutlich auf, wie weit entwickelt dieses Modell also ist und wie komplex es „denken“ kann.
Das Verstehen von langen Kontexten und vor allem von Medien innerhalb eines einzelnen Prompts steht nach Aussage von Google dabei noch auf experimenteller Basis. Wer Gemini 1.5 testen kann, wird standardmäßig noch auf 128.000 Tokens pro Prompt begrenzt (entspricht „GPT-4 Turbo“). Nur eine kleine Gruppe von Tester/innen kann schon auf das 1 Million Token Modell zugreifen. Das sollen über 700.000 Wörter oder über 30.000 Zeilen Code sein – sowie abseits von Texteingaben 11 Stunden Audio oder 1 Stunde Video.
Aber warum Audio und Video? Weil Gemini 1.5 nicht nur ein Chatbot ist, sondern ein multimodales KI-Modell. Es kann also neben Textinformationen auch mit Bildern, Videos und anderen Medien umgehen. Dafür bietet Google verschiedene Beispiele in Videoform an, etwa die Untersuchung des Transkripts vom Funkverkehr der Apollo-11-Mission (erste Mondlandung). Nach Auswertung der entsprechenden PDF wurde eine Zeichnung hochgeladen und gefragt, welche Szene aus dem Transkript sie beschreibt. Die KI konnte sie richtig zuweisen.

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Ein weiteres Video zeigt die Auswertung eines 44-minütigen Films innerhalb von Gemini 1.5. Bei der Auswertung des Films für die folgenden Prompt-Abfragen kamen schon 696.417 Tokens zum Einsatz. Es konnte erfolgreich gefragt werden, bei welchem Timecode eine bestimmte Szene (als Text beschrieben) zu finden ist. Weiterhin konnte eine Zeichnung als Szenenbeschreibung hochgeladen und nach deren Timecode gefragt werden. Auch hier fand das multimodale KI-Modell die richtigen Daten.
Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Weitere Details und Beispiele gibt es im entsprechenden Blog-Beitrag zu Gemini 1.5 von Google.
Was ist eine Token-ID?
Nun müsst ihr kurz alles vergessen, was ihr gerade über Tokens gelernt habt. Denn die Anzahl von Tokens als Messung der Komplexität von Medien, Prompts und Ausgaben spielt hier keine direkte Rolle. Es kommen andere Zahlenwerte zum Einsatz, die eine andere Bedeutung haben. Das nur als Hinweis, da ich selbst bei der Recherche kurz verwirrt war. Denn die Tokenmenge eines Wortes (nach obigen Werten also rund 1,4 Tokens pro Wort) hat nichts mit seiner Token-ID zu tun.
Denn die Token-ID ist, wie der Name schon sagt, eine Identifikationsnummer. Sie ordnet dem Wort, dem Buchstaben einer Abkürzung oder den Einzelelementen eines gebeugten Wortes einen bestimmten Wert zu. Dieser wird mit dem KI-Modell abgeglichen und dann die wahrscheinlichste Kombination von Token-IDs als Antwort ausgegeben. So funktioniert das digitale neurale Netzwerk – es „denkt“ nicht wirklich, sondern arbeitet die wahrscheinlichste Folge von Wörtern und Wortteilen aus, die zur Eingabe passt und formt daraus die Antwort.
Etwas bildlicher ausgedrückt: Token-IDs sind die KI-Sprache, in die Eingaben umgewandelt werden, um eine passende KI-Antwort zu finden, die ihrerseits wieder in Menschensprache konvertiert wird.
Die Token-ID am Beispiel von ChatGPT
Das klingt sicher sehr theoretisch und kompliziert. Und zugegeben, ich habe den Sachverhalt aufgrund einer ähnlichen Beschreibung anfangs auch nicht ganz verstanden. Ein Beispiel, das von OpenAI für den Betrieb des Chatbots ChatGPT gegeben wird, hat mir aber beim besseren Verständnis geholfen. Es zeigt zudem auf, nach welchen Kriterien sich Token-IDs für das gleiche Wort ändern können. Ich habe es euch mal zusammengefasst:
Der Beispielsatz lautet auf Englisch „My favorite color ist red.“ (Meine Lieblingsfarbe ist rot.). Der Punkt am Ende ist 13 Tokens wert. Das letzte Wort davor („red“) 2266 Tokens. Wird das „red“ aber groß geschrieben („Red“), ist es unüblicher und damit 2297 Tokens wert. Wird der Satz zu „Red is my favorite color.“ umgestellt, bleibt der Wert für den Punkt bei 13; der für „Red“ am Anfang steigt aber auf 7738. Das „is“ ist zudem so allgemeingültig, das sein Wert überall bei 318 bleibt.
Das zeigt anschaulich auf, dass einzelne Wörter je nach Verwendung und Position im Prompt mit einem anderen Kontext oder mit einer anderen Bedeutung im gleichen Kontext in Verbindung gebracht werden. Also werden sie in eine andere Token-ID übersetzt, was wiederum eine abweichende Antwort der KI hervorruft. Das erklärt auch, warum das Umstellen von Anfragen zu abweichenden Ausgaben führt, obwohl der Inhalt gleich ist. Weiterhin kann so die Gewichtung von Einzelinhalten verändert werden, um die Antwort eher darauf als auf andere Textteile folgen zu lassen.
Die Token-IDs der eigenen ChatGPT-Eingabe prüfen: So geht’s!
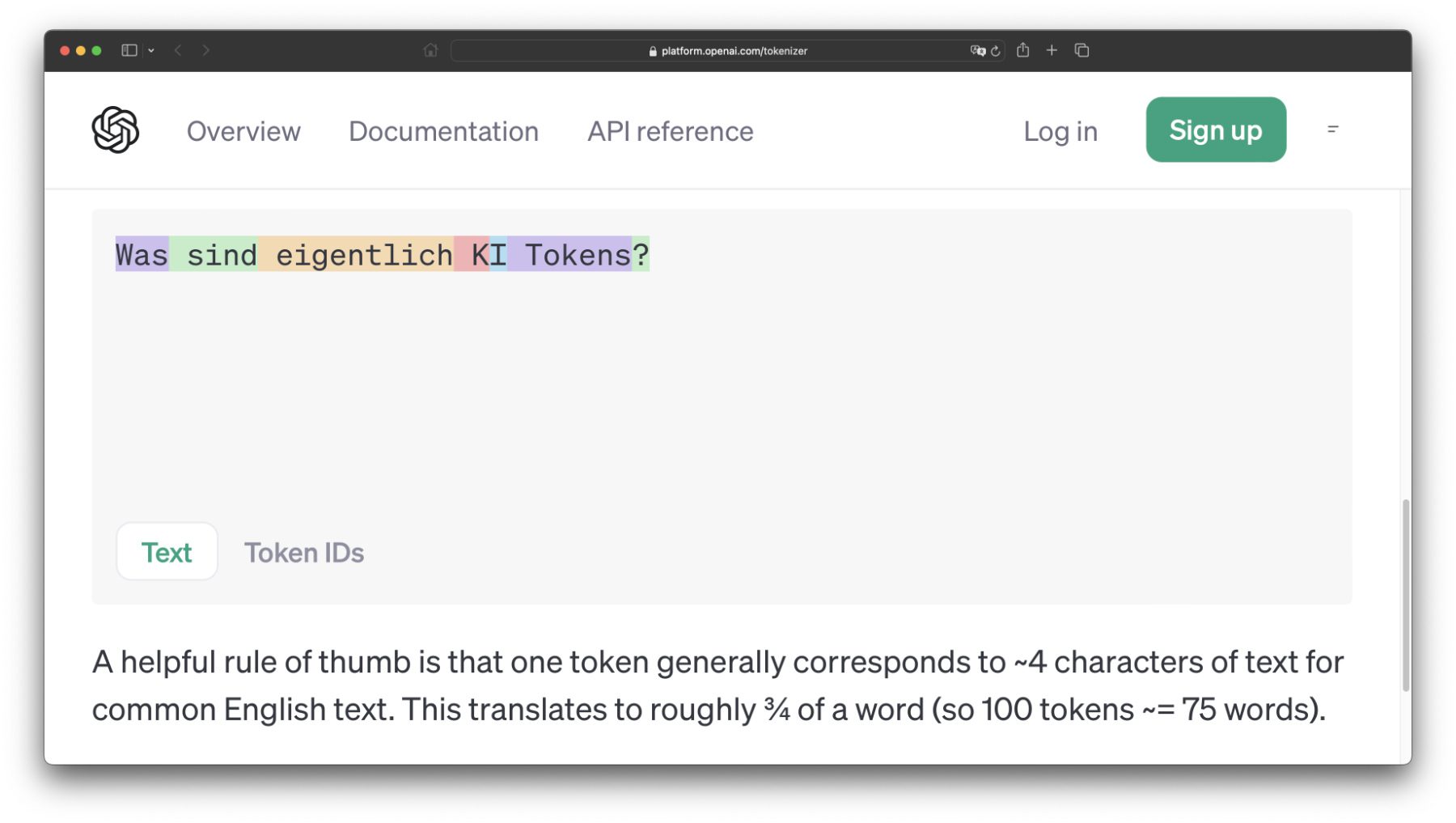
Weiter oben habe ich euch ja zum Berechnen der Tokens eurer Anfrage den OpenAI Tokenizer verlinkt. Dieser bietet neben den Zählfunktionen für die eingegebenen Zeichen und die verbrauchten Tokens auch eine Analyse der Token-IDs an. Mein Beispielsatz „Was sind eigentlich KI Tokens?“ mit seinen 7 Tokens und 30 Zeichen wird dabei in folgende Einzelelemente zerlegt:
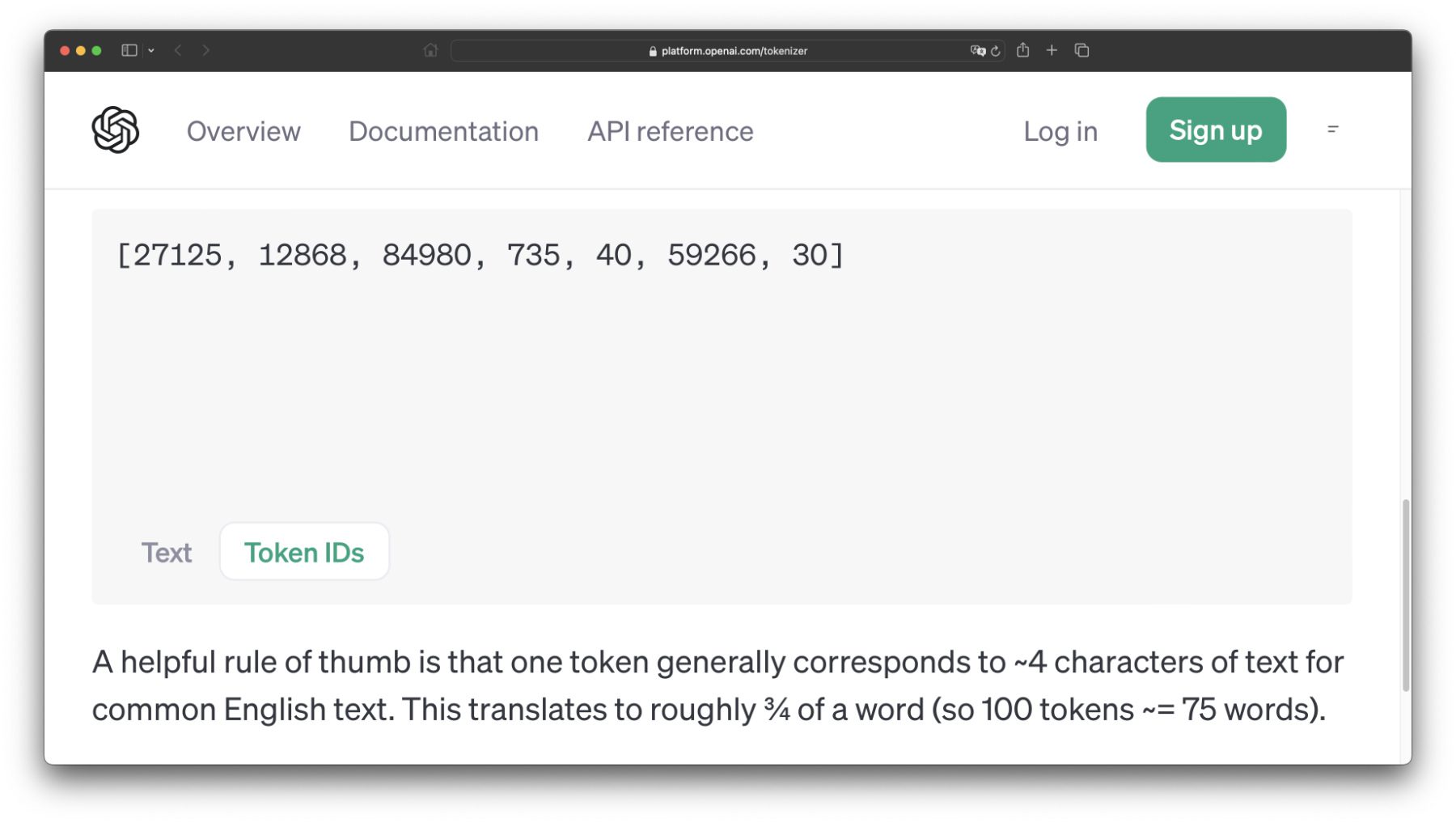
[Was], [ sind], [ eigentlich], [ K], [I], [ Tokens], [?] – Die Token-IDs für diese einzelnen Elemente lauten dabei folgendermaßen: 27125, 12868, 84980, 735, 40, 59266, 30. Das einzelne „I“ ohne zugeordnetes Leerzeichen ist wenig komplex und hat eine ID von 40, das Fragezeichen eine 30. Das Wort „eigentlich“ hat die größte ID. Der englische Satz „What are AI Tokens though?“ mit 6 Tokens und 26 Zeichen bietet folgende Werte: 3923, 527, 15592, 59266, 3582, 30.
Fazit zu den Themen KI-Token und Token-ID
Die Anzahl der möglichen Tokens bei der Nutzung von Chatbots und multimodalen KIs gibt an, wie lang bzw. komplex die Eingaben und Ausgaben sein können. Von langen, detaillierten Textprompts bis hin zur Auswertung von ganzen Filmen ist dabei schon vieles möglich und wird bereits mit Token-Mengen in Millionenhöhe angegeben – während einfache Alltagsfragen an Chatbots kaum im zweistelligen Token-Bereich landen. Lange Antworten können allerdings in den dreistelligen Bereich gelangen, was ebenfalls bei der Nutzung zu beachten ist.
Gleichzeitig gibt es den Wert der Token-ID, der mit der Anzahl von Buchstaben weniger zu tun hat. Die ID, welche in der KI-Sprache einem Wort gleichkommt, ergibt sich eher aus der Nutzungshäufigkeit des Wortes, der Abkürzung oder des Zeichens sowie der Positionierung im jeweiligen Satz. Je komplexer oder unüblicher, desto höher die ID. Es muss zur Verarbeitung also auf einen größeren Trainingssatz, auf einen größeren Bereich des Modell-Netzwerks zugegriffen werden. Das ist das KI-Pendant zum Wissensschatz von Menschen. Er muss größer ausfallen, um komplexere Fragen beantworten zu können.
Ähnliche Beiträge

Qi2-Ladegerät mit Lüfter: Perfekt für den Sommer oder kompletter Quatsch?
Soundcore AeroClip: Open-Ear-Kopfhörer mit offenem Ring-Design
Mit MagSafe und Qi2: Pitaka Powerbank fürs iPhone ausprobiert
Was ist eine „virtuelle Softwarekarte“ auf der Nintendo Switch?
iVANKY Fusion Dock Pro 3 – 11-in-1 Thunderbolt 5 Dock günstiger kaufen
Mac-Hilfe: Bluetooth deaktiviert und Maus / Trackpad lässt sich nicht mehr nutzen
Manus – KI-Agent für komplexe Aufgaben (+ Open-Source-Alternative)
Europäischer Suchindex: Ecosia und Qwant arbeiten an Google-Alternative








Johannes hat nach dem Abitur eine Ausbildung zum Wirtschaftsassistenten in der Fachrichtung Fremdsprachen absolviert. Danach hat er sich aber für das Recherchieren und Schreiben entschieden, woraus seine Selbstständigkeit hervorging. Seit mehreren Jahren arbeitet er nun u. a. für Sir Apfelot. Seine Artikel beinhalten Produktvorstellungen, News, Anleitungen, Videospiele, Konsolen und einiges mehr. Apple Keynotes verfolgt er live per Stream.